
Imagine a warehouse AI agent that sees an unexpected drop in inventory levels at 2 AM. It must decide: raise a purchase order now, or wait for a human to review?
That decision to act or wait depends on a single internal number called the confidence score.
Confidence scoring in AI agents is the mechanism that tells an autonomous system how certain it is about its prediction, decision, or action. It is the difference between an AI that acts when it should, waits when it must, and escalates when it cannot tell the difference on its own.
In supply chains where one wrong decision can cascade into missed SLAs, excess inventory, or broken customer promises this number is not a technical detail.
This blog explains what confidence scoring is, how AI agents in supply chain use it, where it is applied, and how teams can build systems that are not just smart but also trustworthy.

A confidence score is a number between 0 and 1 that represents how certain an AI model is about a prediction or action it is about to take.
This is the most important thing to understand about LLM confident scoring model can express high confidence and still be wrong.
Amazon's 2025 research paper on confidence scoring for LLM-generated SQL in supply chain data extraction found that LLMs are often overconfident in their own outputs. When asked to rate their own certainty, they consistently overstated it.
This is why you cannot rely on self-reported confidence alone. You need external validation methods, comparing outputs, using semantic similarity checks, or building in structured feedback loops.

In practice, AI decision threshold systems use one or more of these methods:
Agentic AI supply chain systems are not dashboards that recommend actions. They actually execute decisions by raising purchase orders, rerouting shipments, adjusting production schedules, and committing to delivery promises.
According to IBM's research, 62% of supply chain leaders say AI agents embedded in operational workflows accelerate speed to action. Gartner predicts that by 2028, 33% of enterprise software applications will include agentic AI up from less than 1% in 2024.
When agents act autonomously at this scale, the question is not "can the AI do it?" but "does the AI know when not to do it?" That is the core job of confidence scoring.
Here is what happens when supply chain AI automation runs without proper confidence controls:
In all of these cases, the agent acted. The confidence score would have told it to pause.
Human-in-the-loop AI is not a fallback for when AI fails. It is a deliberate design choice. Confidence scoring defines the boundary:
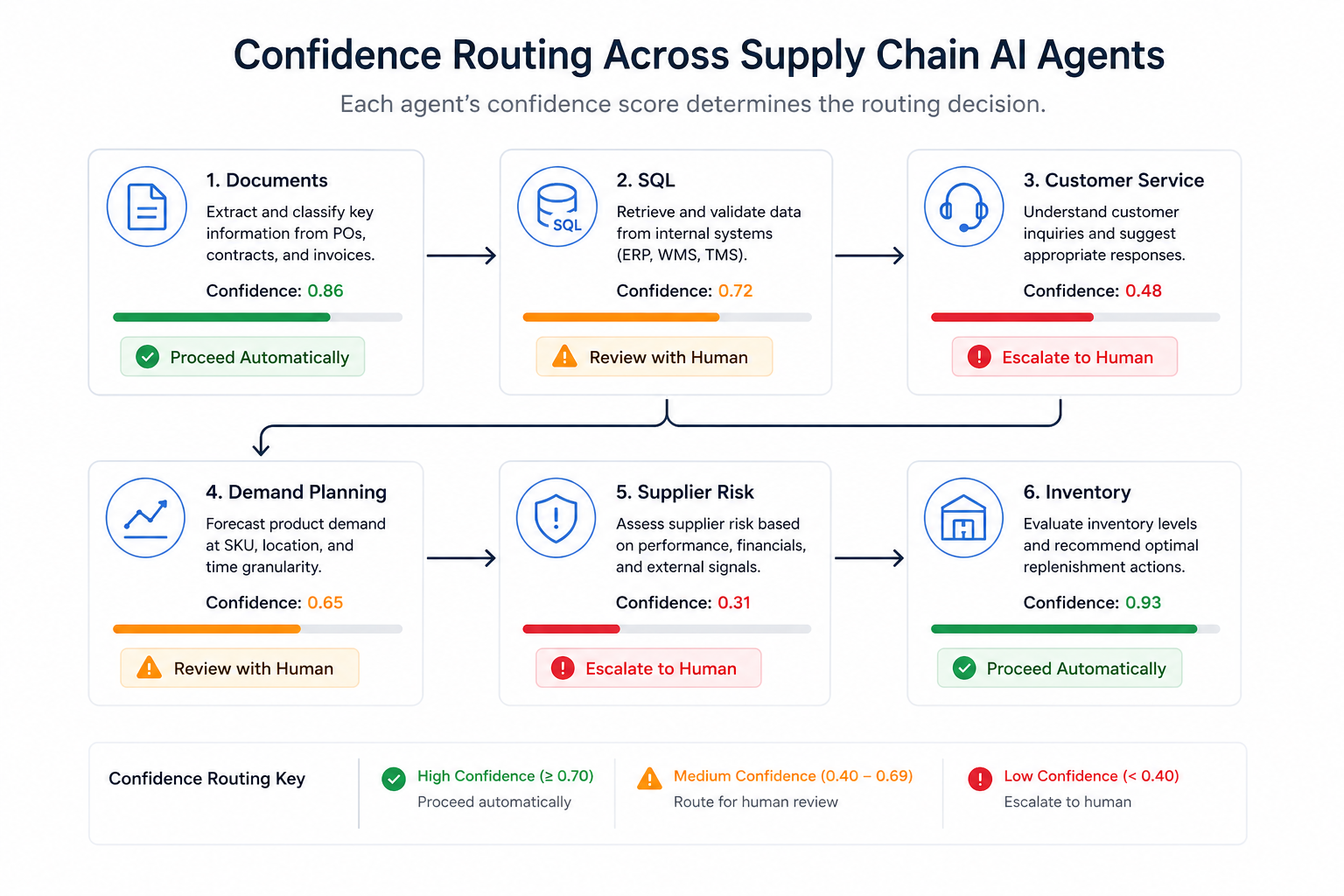
Autonomous AI agents logistics teams deploy confidence scoring across every major function
Every extracted document is evaluated by an LLM judge for consistency, completeness, and confidence. Based on that score, the routing engine makes an automatic decision:
| Confidence Level | Action Taken |
|---|---|
| High confidence | Auto-accepted and indexed |
| Medium confidence | Flagged for quick human review |
| Low confidence | Sent for expert review |
| Very low confidence | Rejected and reprocessed from earlier stages |
Low-confidence documents are not simply discarded. They are rerouted to the OCR or layout extraction stage for targeted reprocessing ,not a full pipeline restart.
Non-technical supply chain managers often interact with data using natural language "show me all suppliers with delivery delays over 5 days in Q1."
An LLM translates this into a SQL query.
Amazon's research showed that when the LLM's SQL was evaluated using embedding-based semantic similarity rather than the model's own confidence rating, the system was significantly better at catching errors. This matters
enormously: a wrong SQL query in a supply chain system can pull incorrect inventory data, trigger unnecessary reorders, or miss critical shortage signals.
The AI escalation models used in contact centres and logistics customer support follow a three-input framework:
When AI escalates without transferring context, the customer must repeat everything to a human agent. That is a trust failure. Good escalation design means the human agent receives the full conversation history, the intent the AI detected, and the actions already attempted.
Agentic AI supply chain demand planning systems run a continuous sense,decide,act, learn. Before executing a delta-based replan adjusting production quantities, procurement volumes, or distribution flows ,the agent simulates trade-offs in a digital twin environment.
This simulation is effectively a structured confidence check: does the proposed action improve service levels and cost outcomes without introducing downstream disruption? Only validated decisions are pushed to the APS or MRP system.
Procurement AI agents continuously score supplier health using signals like OTIF performance, shipment delays, quality incidents, and credit indicators.
When a supplier's risk score crosses a predefined threshold, the agent triggers governed sourcing nudges "reduce allocation by 20%" or "initiate dual sourcing."
Higher-impact decisions are escalated to procurement managers with pre-evaluated options already ranked, so human approval happens faster without restarting the sourcing process from scratch.
Adaptive inventory agents recalibrate min/max thresholds based on demand variability, lead times, and service-level targets. Before updating live parameters in the ERP, the agent tests the proposed change in a simulation layer. If the scenario improves fill rates without introducing warehouse congestion or labour issues, the change is applied. If not low confidence in the outcome the agent holds the recommendation for planner review.
A threshold is the minimum confidence score required for an agent to act automatically. Setting it correctly is a balancing act.
What Happens When You Change the Threshold?
| Threshold Direction | Effect on Precision | Effect on Recall |
|---|---|---|
| Raise the threshold | Fewer wrong approvals (higher precision) | More correct answers get sent for review (lower recall) |
| Lower the threshold | More correct answers pass automatically (higher recall) | More wrong answers slip through (lower precision) |
There is no universally correct threshold. It depends on the cost of being wrong in your specific use case.
For Example :
In supply chain purchase orders, a high-value, non-reversible order needs 90%+ confidence before autonomous execution. A small safety stock replenishment order for a fast-moving SKU can be approved at 75%.
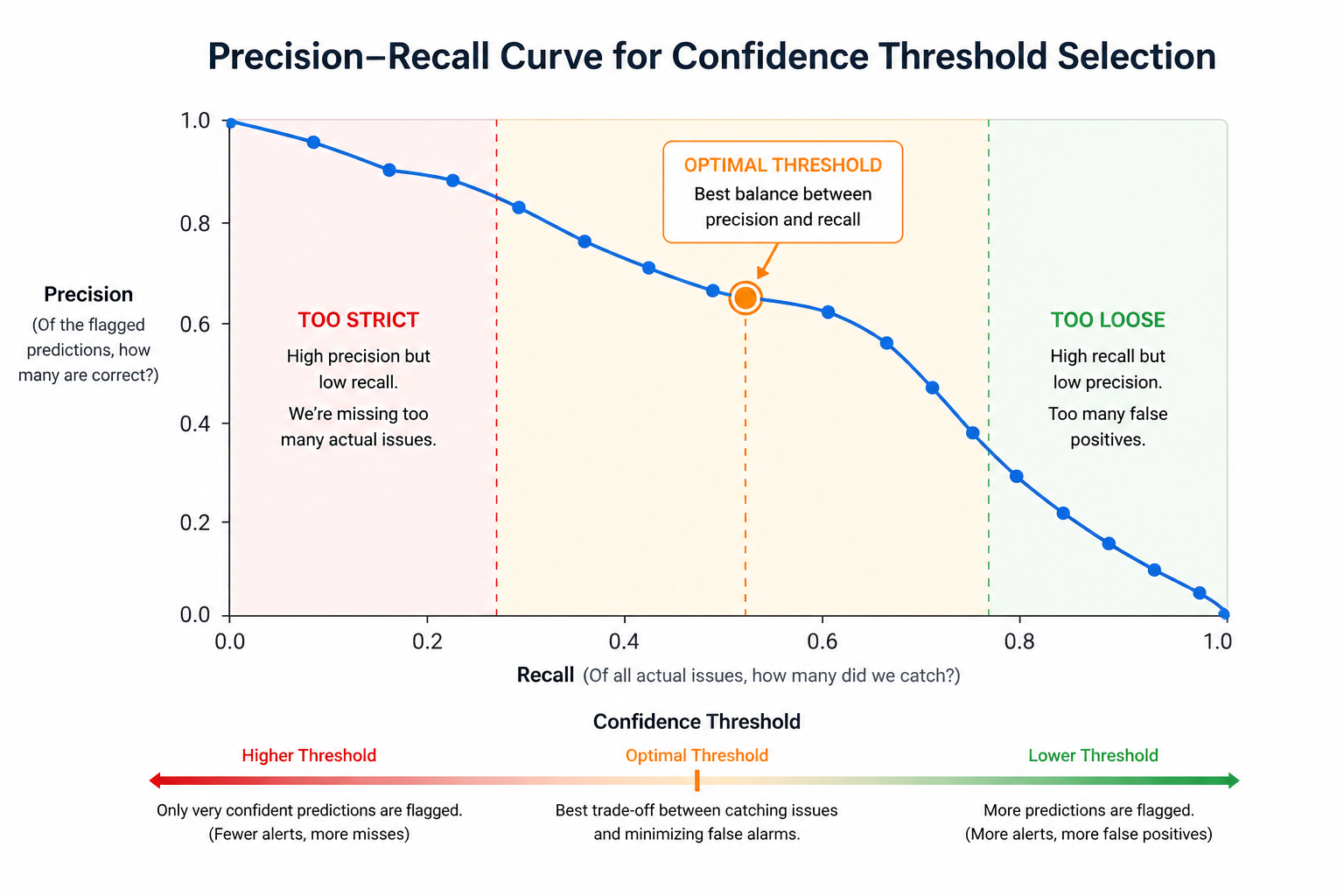
The best way to find the right threshold is to plot a precision-recall curve. You run your model on a test dataset at many different threshold values and record precision and recall for each. The curve shows you the trade-off visually, and you pick the point that matches your business risk tolerance.
For example, Mindee, a document AI company, tested this on 10,000 annotated receipts from 20 countries and used the resulting PR curve to set field-level confidence thresholds for each extracted data type: invoice date, total amount, tax, and so on.
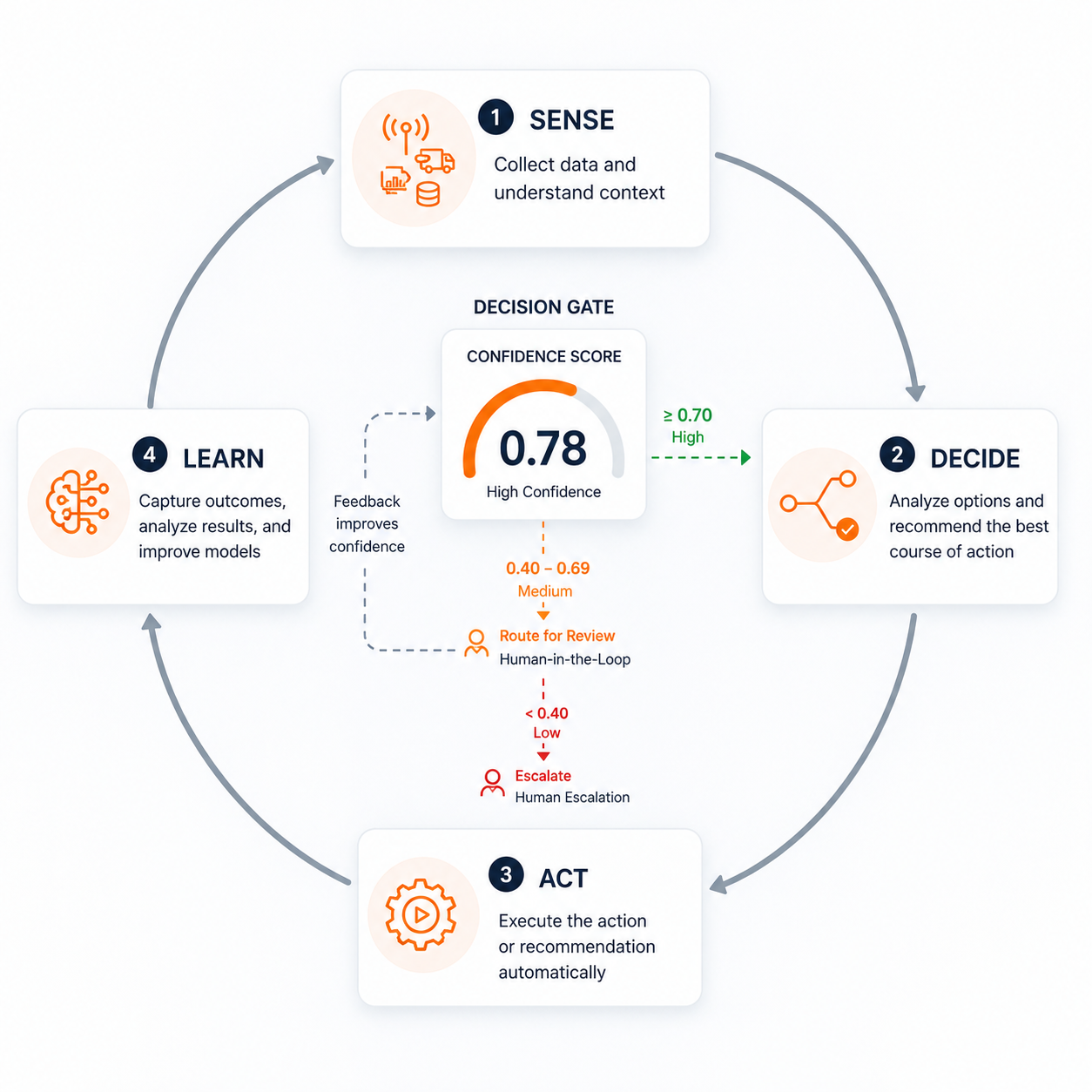
A self-healing supply chain is one that can detect problems, diagnose root causes, and trigger corrective actions, all without waiting for a human to notice the issue and escalate it.
Confidence scoring is what makes this possible. Without it, an agent that detects a disruption cannot safely act, as it does not know whether its diagnosis is reliable enough to warrant action.
The operational pattern of a self-healing supply chain looks like this:
Over time, the system needs fewer human interventions for the same class of documents. The confidence scores become more calibrated. The automation rate improves. This is what continuous improvement looks like in agentic AI systems.
Never use self-reported scores as your only validation layer.
A 0.75 threshold that works for small replenishment orders is dangerously low for high-value purchase commitments. Map thresholds to risk levels, not to the model type.
If the AI escalates but the human agent receives no transcript, no intent summary, and no list of actions already tried, the escalation is a failure. The customer experiences it as being punished for using automation.
If corrected outputs are not fed back into the model, the confidence scores never improve. The system will keep making the same mistakes at the same rate, and humans will keep overriding it at the same frequency.
Supply chain data is complex and often inconsistent. Test your confidence scoring logic against adversarial inputs incomplete data, conflicting signals, ambiguous user queries before putting agents into production.
As agentic AI supply chain systems mature, confidence scoring will move from a backend metric to a first-class operational signal. Here is what is coming:
When multiple specialised agents collaborate, a demand agent, a logistics agent, a safety agent, and a supplier risk agent all contribute to the same decision ,each agent's confidence score must be aggregated into a single decision confidence.
Operations teams will monitor agent confidence the way they monitor KPIs today, tracking which decision types have declining confidence scores as leading indicators of data quality issues or model drift.
In autonomous AI agents' logistics, when an agent is 95% confident in a delivery date, it commits. When it is 70% confident, it communicates a range instead. Customers receive honest, uncertainty-aware commitments rather than promises the system cannot keep.
As AI regulation increases globally, confidence scores will form the foundation of AI decision audit trails showing regulators not just what the AI decided, but how sure it was, and what human oversight was applied.
A confidence score is a number between 0 and 1 that represents how certain an AI model is about a prediction or action it is about to take.
Scoring allows AI to handle routine tasks autonomously, ensuring you gain efficiency without the bottleneck of manual review for every decision.
Assign higher thresholds (0.90+) to high-risk decisions and lower ones (0.70+) to routine tasks, balancing error costs via precision-recall curves.
Accuracy measures historical performance on a test set, while confidence measures how certain the model is about a specific, real-time prediction.
It flags most uncertainties, but since models can occasionally be "confidentially wrong," it should be paired with human review and external validation.
![]() We use cookie
files.
We use cookie
files.
We activate all cookies by default to ensure the proper functioning
of our website,
advertisement, and analytics according to the
Privacy Policy.